AI Explainability 360 - Resources
Welcome to AI Explainability 360
We hope you will use it and contribute to it to help engender trust in AI by making machine learning more transparent.
Black box machine learning models that cannot be understood by people, such as deep neural networks and large ensembles, are achieving impressive accuracy on various tasks. However, as machine learning is increasingly used to inform high stakes decisions, explainability and interpretability of the models is becoming essential. There are many ways to explain: data vs. model, directly interpretable vs. post hoc explanation, local vs. global, static vs. interactive; the appropriate choice depends on the persona of the consumer of the explanation.
The AI Explainability 360 Python package includes algorithms that span the different dimensions of ways of explaining along with proxy explainability metrics. The AI Explainability 360 interactive demo provides a gentle introduction to the concepts and capabilities by walking through an example use case from the perspective of different consumer personas. The tutorials and other notebooks offer a deeper, data scientist-oriented introduction. The complete API is also available.
Being a comprehensive set of capabilities, it may be confusing to figure out which class of algorithm is most appropriate for a given use case. To help, we have created some guidance material that can be consulted.
We have developed the package with extensibility in mind. We encourage the contribution of your explainability metrics and algorithms. Please join the community to get started as a contributor. The set of implemented metrics and algorithms includes ones described in the following list of papers:
- David Alvarez-Melis, and Tommi Jaakkola, “Towards Robust Interpretability with Self-Explaining Neural Networks”, Conference on Neural Information Processing Systems, 2018.
- Sanjeeb Dash, Oktay Günlük, and Dennis Wei, “Boolean Decision Rules via Column Generation”, Conference on Neural Information Processing Systems, 2018.
- Amit Dhurandhar, Pin-Yu Chen, Ronny Luss, Chun-Chen Tu, Paishun Ting, Karthikeyan Shanmugam, and Payel Das, “Explanations Based on the Missing: Towards Contrastive Explanations with Pertinent Negatives”, Conference on Neural Information Processing Systems, 2018.
- Amit Dhurandhar, Karthikeyan Shanmugam, Ronny Luss, and Peder Olsen, "Simple Models with Confidence Profiles”, Conference on Neural Information Processing Systems, 2018.
- Karthik S. Gurumoorthy, Amit Dhurandhar, Guillermo Cecchi, and Charu Aggarwal “Efficient Data Representation by Selecting Prototypes with Importance Weights”, IEEE International Conference on Data Mining, 2019.
- Michael Hind, Dennis Wei, Murray Campbell, Noel C. F. Codella, Amit Dhurandhar, Aleksandra Mojsilović, Karthikeyan Natesan Ramamurthy, and Kush R. Varshney, “TED: Teaching AI to Explain Its Decisions”, AAAI/ACM Conference on Artificial Intelligence, Ethics, and Society, 2019.
- Abhishek Kumar, Prasanna Sattigeri, and Avinash Balakrishnan, “Variational Inference of Disentangled Latent Concepts from Unlabeled Data”, International Conference on Learning Representations, 2018.
- Ronny Luss, Pin-Yu Chen, Amit Dhurandhar, Prasanna Sattigeri, Karthikeyan Shanmugam, and Chun-Chen Tu, “Leveraging Latent Features for Local Explanations”, ACM Conference on Knowledge Discovery and Data Mining, 2021.
- Dennis Wei, Sanjeeb Dash, Tian Gao, and Oktay Günlük, “Generalized Linear Rule Models”, International Conference on Machine Learning, 2019.
Guidance on choosing algorithms
AI Explainability 360 (AIX360) includes many different algorithms capturing many ways of explaining [1], which may result in a daunting problem of selecting the right one for a given application. We provide some guidance to help. The following decision tree will help you in selecting. The text below provides further exposition.
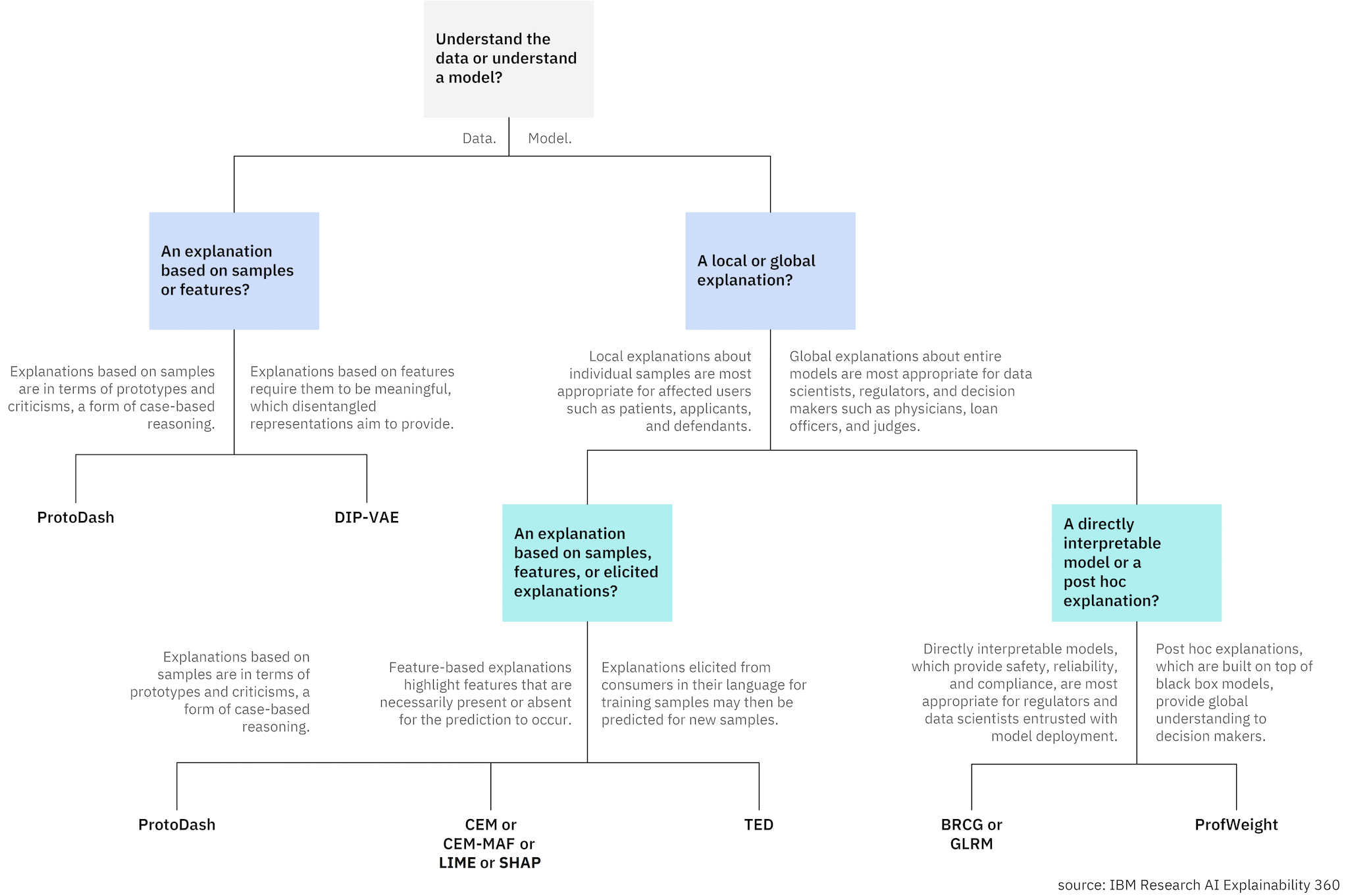
Appropriateness of toolkit
The algorithms in the toolkit are primarily intended for high-stakes applications of machine learning from data that support decision making with humans in the loop, either as the decision makers, the subjects of the decisions, or as regulators of the decision making processes. Other modes of AI such as knowledge graph induction or planning, and even other modes of machine learning such as reinforcement learning are not appropriate settings in which to use AIX360.
Data explanation
Machine learning begins with data. It is often useful for people to understand the characteristics of the data and the features of the data before any supervised learning takes place.
Sometimes the features in a given dataset are meaningful to consumers, but other times they are entangled, i.e. multiple meaningful attributes are combined together in a single feature. The Disentangled Inferred Prior Variational Autoencoder (DIP-VAE) algorithm is an unsupervised representation learning algorithm that will take the given features and learn a new representation that is disentangled in such a way that the resulting features are understandable.
An alternative way to understand a dataset is through prototypes (samples that relay the essence of a dataset) and criticisms (samples that are outliers). The ProtoDash algorithm will extract such prototypes and criticisms to help a consumer understand a dataset’s properties.
Model explanation
There are several ways to make a machine learning model comprehensible to consumers. The first distinction is direct interpretability vs. post hoc explanation [2]. Directly interpretable models are model formats such as decision trees, Boolean rule sets, and generalized additive models, that are fairly easily understood by people and learned straight from the training data. Post hoc explanation methods first train a black box model and then build another explanation model on top of the black box model. The second distinction is global vs. local explanation. Global explanations are for entire models whereas local explanations are for single sample points. AIX360 contains model explanation methods for all of these categories of explanation.
Global directly interpretable models are important for personas that need to understand the entire decision making process and ensure its safety, reliability, or compliance. Such personas include regulators and data scientists responsible for the deployment of systems. Global post hoc explanations are useful for decision maker personas that are being supported by the machine learning model. Physicians, judges, and loan officers develop an overall understanding of how the model works, but there is necessarily a gap between the black box model and the explanation. Therefore, a global post hoc explanation may hide some safety issues but its antecedent black box model may have favorable accuracy. Local models are the most useful for affected user personas such as patients, defendants, and applicants who need to understand the decision on a single sample (theirs).
Global directly interpretable models
The initial release of AIX360 contains two global directly interpretable model learning algorithms: Boolean Decision Rules via Column Generation (Light Edition) and Generalized Linear Rule Models. Both are applicable for classification problems whereas Generalized Linear Rule Models also applies to regression problems. Both have logical conjunctions, i.e. ‘and’-rules of features as their starting point. Boolean Decision Rules combines ‘and’-rules with a logical ‘or’ whereas Generalized Linear Rule Models combines them with weights. For classification problems, Boolean Decision Rules tends to return simple models that can be quickly understood, whereas Generalized Linear Rule Models can achieve higher accuracy while retaining the interpretability of a linear model.
Global post hoc explanations
The initial release of AIX360 contains one algorithm for producing a global post hoc explanation specifically from a neural network as the base black box model. ProfWeight probes into the neural network and produces instance weights that are then applied to training data to learn a directly interpretable model.
Local directly interpretable models
The initial release of AIX360 contains one method, Teaching AI to Explain Its Decisions (TED), that directly learns a model to provide explanations at the sample level. This algorithm is unique in that it requires a training set to have not only features and labels, but also training explanations for each sample collected in the language of the consumer. It then predicts an explanation along with a label from the features of new unseen samples.
Local post hoc explanations
Among local post hoc explanation methods, the initial release of AIX360 contains two variants of the Contrastive Explanations Method. The first variant of the Contrastive Explanations Method is the basic version for classification with numerical features and presents minimally sufficient features as well as minimally and critically absent features for a prediction. The second variant, Contrastive Explanations Method with Monotonic Attribute Functions, is specific for image data, with a particular focus on colored images and images with rich structure. ProtoDash, discussed earlier in data explanation, can also be used for local post hoc model explanation via prototypes.
Developer tutorials
The following tutorials provide different examples of explaining. View them individually below or open the set of Jupyter notebooks in GitHub.
Credit approval
See how to explain credit approval models using the FICO Explainable Machine Learning Challenge dataset. This tutorial demos three explanation methods for three different target consumers.
- Directly interpretable rule-based models for data scientists
- Prototypical examples for loan officers
- Contrastive explanations for customers
Medical expenditure
See how to create interpretable machine learning models in a care management scenario using Medical Expenditure Panel Survey data.
Dermoscopy
See how to explain dermoscopic image datasets used to train machine learning models that help physicians diagnose skin diseases.
Health and Nutrition Survey
See how to quickly understand the National Health and Nutrition Examination Survey datasets to hasten research in epidemiology and health policy.
Proactive Retention
See how to explain predictions of a model that recommends employees for retention actions from a synthesized human resources dataset.
Papers
- AI Explainability 360: Impact and Design, Vijay Arya, Rachel K. E. Bellamy, Pin-Yu Chen, Amit Dhurandhar, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Q. Vera Liao, Ronny Luss, Aleksandra Mojsilovic, Sami Mourad, Pablo Pedemonte, Ramya Raghavendra, John Richards, Prasanna Sattigeri, Karthikeyan Shanmugam, Moninder Singh, Kush R. Varshney, Dennis Wei, Yunfeng Zhang, arXiv preprint, arXiv:2109.12151, 2021
- One Explanation Does Not Fit All: A Toolkit and Taxonomy of AI Explainability Techniques, Vijay Arya, Rachel K. E. Bellamy, Pin-Yu Chen, Amit Dhurandhar, Michael Hind, Samuel C. Hoffman, Stephanie Houde, Q. Vera Liao, Ronny Luss, Aleksandra Mojsilović, Sami Mourad, Pablo Pedemonte, Ramya Raghavendra, John Richards, Prasanna Sattigeri, Karthikeyan Shanmugam, Moninder Singh, Kush R. Varshney, Dennis Wei, Yunfeng Zhang, arXiv preprint arXiv:1909.03012, 2019
Glossary
Black box model
A complicated model that consumers are not easily able to understand, such as a deep neural network.
Classifier
A model that predicts categorical labels from features.
Consumer
A human receiving an explanation.
Directly interpretable model
A model that consumers can usually understand, such as a simple decision tree or Boolean rule set.
Disentangled representation
A representation in which changes to one feature leave other features unchanged.
Explanation
A reason or justification for the predicted label. Some experts differentiate explanations from interpretations. Explanations come from surrogate models and interpretations come from the models themselves.
Feature
An attribute containing information for predicting the label.
Global explanation
An explanation for an entire model.
Label
A value indicating the outcome or category for a sample.
Local explanation
An explanation for a sample.
Machine learning
A general approach for determining models from data.
Modality
The type of data, such as tabular data, images, audio signals, or natural language text.
Model
A function that takes features as input and predicts labels as output.
Persona
The role of the consumer, such as a decision maker, regulator, data scientist, or patient.
Post hoc explanation
An explanation coming from a model that approximates a black box model. The experts that differentiate the terms explanation and interpretation limit the term explanation only to post hoc explanation.
Prototype
A sample that exhibits the essence of a dataset.
Regressor
A model that predicts numerical labels from features.
Representation
A mathematical transformation of data into features suitable for models.
Sample
A single data point, instance, or example.
Score
A continuous valued output from a classifier. Applying a threshold to a score results in a predicted label.
Supervised learning
Determining models from data having features and labels.
Training data
A dataset from which a model is learned.
Unsupervised learning
Determining models or representations from data having only features, no labels.
Related Trusted AI Technologies
Fairness
Machine learning models are increasingly used to inform high stakes decisions about people. Although machine learning, by its very nature, is always a form of statistical discrimination, the discrimination becomes objectionable when it places certain privileged groups at systematic advantage and certain unprivileged groups at systematic disadvantage. The AI Fairness 360 toolkit includes a comprehensive set of metrics for datasets and models to test for biases, explanations for these metrics, and algorithms to mitigate bias in datasets and models. The AI Fairness 360 interactive demo provides a gentle introduction to the concepts and capabilities of the toolkit. The package includes tutorials and notebooks for a deeper, data scientist-oriented introduction.
To learn more about this toolkit, visit IBM Research AI Fairness 360.
Privacy
Many privacy regulations, including GDPR, mandate that organizations abide by certain privacy principles when processing personal information. This is also relevant for AI models trained using personal data, since it has been shown that trained ML models may leak sensitive information about their training sets. The AI Privacy 360 toolkit includes novel tools to support the assessment of privacy risks of AI-based solutions, and to enable them to adhere to such privacy requirements.
To learn more about this toolbox, visit IBM Research AI Privacy 360.
Adversarial Robustness
The number of reports of real-world exploitations using adversarial attacks against AI is growing, highlighting the importance of understanding, improving, and monitoring the adversarial robustness of AI models. The Adversarial Robustness 360 Toolkit provides a comprehensive and growing set of tools to systematically assess and improve the robustness of AI models against adversarial attacks, including evasion and poisoning.
To learn more about this toolkit, visit IBM Research Adversarial Robustness 360.
Uncertainty Quantification
Uncertainty quantification gives AI the ability to express that it is unsure, adding critical transparency for the safe deployment and use of AI. Uncertainty Quantification 360 is an extensible open-source toolkit with a Python package that provides data science practitioners and developers access to state-of-the-art algorithms, to streamline the process of estimating, evaluating, improving, and communicating uncertainty of AI and machine learning models.
To learn more about this toolkit, visit IBM Research Uncertainty Quantification 360.
Transparency and Governance
There is an increasing call for AI transparency and governance. The FactSheets project's goal is to foster trust in AI by increasing understanding and governance of how AI was created and deployed. The FactSheet 360 website includes many example FactSheets for publically available models, a methodology for creating useful FactSheet templates, an illustration of how FactSheets can be used for AI governance, and various resources, such as over 24 hours of video lectures.
To learn more about this project, visit IBM Research AI FactSheets 360.